Understanding the reporting data model: Overview and query design
Overview
The Reporting Data Model is a dimensional model that allows customized reporting. Dimensional modeling is a data warehousing technique that exposes a model of information around business processes while providing flexibility to generate reports. The implementation of the Reporting Data Model is accomplished using the PostgreSQL relational database management system. As a result, the syntax, functions, and other features of PostgreSQL can be utilized when designing reports against the Reporting Data Model.
The Reporting Data Model is available as an embedded relational schema that can be queried against using a custom report template. When a report is configured to use a custom report template, the template is executed against an instance of the Reporting Data Model that is scoped and filtered using the settings defined with the report configuration. The following settings will dictate what information is made available during the execution of a custom report template.
Report Owner
The owner of the report dictates what data is exposed with the Reporting Data Model. The report owner’s access control and role specifies what scope may be selected and accessed within the report.
Scope Filters
Scope filters define what assets, asset groups, sites, or scans will be exposed within the reporting data model. These entities, along with matching configuration options like “Use only most recent scan data”, dictate what assets will be available to the report at generation time. The scope filters are also exposed within dimensions to allow the designer to output information embedded within the report that identify what the scope was during generation time, if desired.
Vulnerability Filters
Vulnerability filters define what vulnerabilities (and results) will be exposed within the data model. There are three types of filters that are interpreted prior to report generation time:
- Severity: filters vulnerabilities into the report based on a minimum severity level.
- Categories: filters vulnerabilities into or out of the report based on metadata associated to the vulnerability.
- Status: filters vulnerabilities into the report based on what the result status is.
Query design
Access to the information in the Reporting Data Model is accomplished by using queries that are embedded into the design of the custom report templates.
Dimensional Modeling
Dimensional Modeling presents information through a combination of facts and dimensions. A fact is a table that stores measured data, typically numerical and with additive properties. Fact tables are named with the prefix “fact_” to indicate they store factual data. Each fact table record is defined at the same level of grain, which is the level of granularity of the fact. The grain specifies the level at which the measure is recorded.
Dimension is the context that accompanies measured data and is typically textual. Dimension tables are named with the prefix “dim_” to indicate that they store context data. Dimensions allow facts to be sliced and aggregated in ways meaningful to the business. Each record in the fact table does not specify a primary key but rather defines a one-to-many set of foreign keys that link to one or more dimensions. Each dimension has a primary key that identifies the associated data that may be joined on. In some cases the primary key of the dimension is a composite of multiple columns. Every primary key and foreign key in the fact and dimension tables are surrogate identifiers.
Normalization & Relationships
Unlike traditional relational models, dimensional models favor denormalization to ease the burden on query designers and improve performance. Each fact and its associated dimensions comprise what is commonly referred to as a “star schema”. Visually a fact table is surrounded by multiple dimension tables that can be used to slice or join on the fact. In a fully denormalized dimensional model that uses the star schema style there will only be a relationship between the fact and a dimension, but the dimension is fully self-contained. When the dimensions are not fully denormalized they may have relationships to other dimensions, which can be common when there are one-to-many relationships within a dimension. When this structure exists, the fact and dimensions comprise a “snowflake schema”. Both models share a common pattern which is a single, central fact table. When designing a query to solve a business question, only one schema (and thereby one fact) should be used.
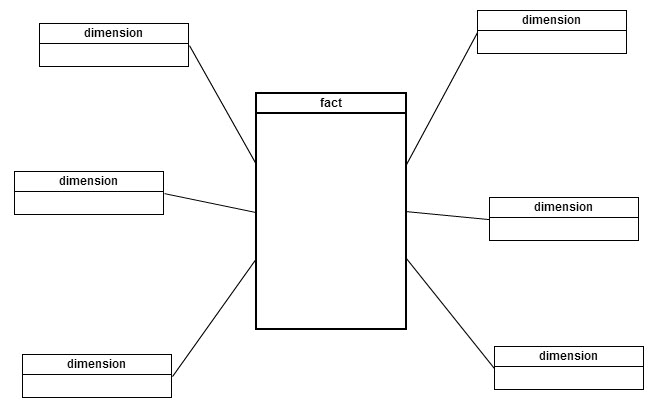
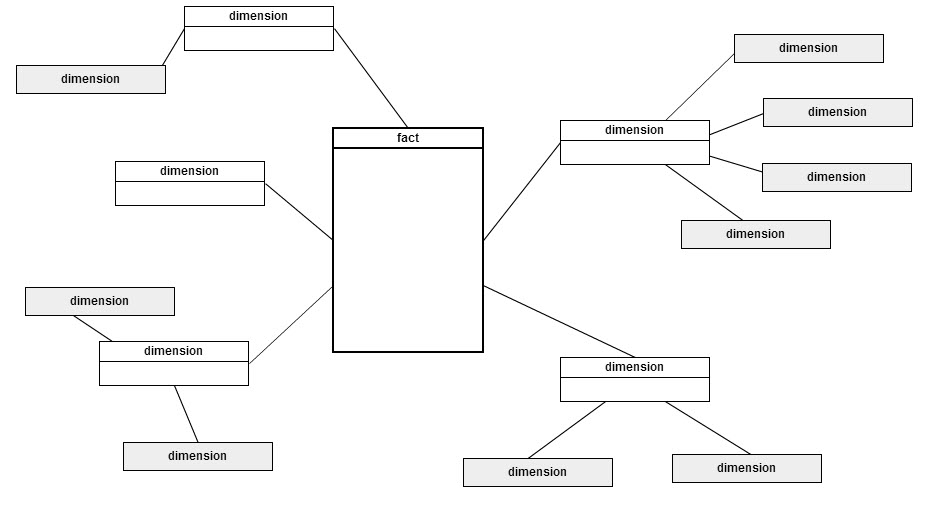
Fact Table Types
There exist three different types of fact tables: (1) transaction (2) accumulating snapshot and (3) periodic snapshot. The level of grain of a transaction fact is an event that takes place at a certain point in time. Transaction facts identify measurements that accompany a discrete action, process, or activity that is performed on a non-regular interval or schedule. Accumulating snapshot facts aggregate information that is measured over time or multiple events into a single consolidated measurement. The measurement shows the current state at a certain level of grain. The periodic snapshot fact table provides measurements that are recorded on a regular interval, typically by day or date. Each record measures the state at a discrete moment in time.
Dimension Table Types
Types Dimension tables are often classified based on the nature of the dimensional data they provided, or to indicate the frequency (if any) with which they are updated.
Following are the types of dimensions frequently encountered in a dimensional model, and those used by the Reporting Data Model:
- slowly changing dimension (SCD). A slowly changing dimension is a dimension whose information changes slowly over time at non-regular intervals. Slowly changing dimensions are further classified by types, which indicate the nature by which the records in the table change. The most common types used in the Reporting Data Model are Type I and Type II.
- Type I SCD overwrites the values of the dimensional information over time, therefore it accumulates the present state of information and no historical state.
- Type II SCD inserts into values into the dimension over time and accumulates historical state.
- conformed dimension. A conformed dimension is one which is shared by multiple facts with the same labeling and values.
- junk dimensions. Junk dimensions are those which do not naturally fit within traditional core entity dimensions. Junk dimensions are usually comprised of flags or other groups of related values.
- normal dimension. A normal dimension is one not labeled in any of the other specialized categories.
Null Values & Unknown
Within a dimensional model it is an anti-pattern to have a NULL value for a foreign key within a fact table. As a result, when a foreign key to a dimension does not apply, a default value for the key will be placed in the fact record (the value of -1). This value will allow a “natural” join against the dimension( s) to retrieve either a “Not Applicable” or “Unknown” value. The value of “Not Applicable” or “N/A” implies that the value is not defined for the fact record or dimension and could never have a valid value. The value of “Unknown” implies that the value could not be determined or assessed, but could have a valid value. This practice encourages the use of natural joins (rather than outer joins) when joining between a fact and its associated dimensions.
Query Language
As the dimensional model exposed by the Reporting Data Model is built on a relational database management system, the queries to access the facts and dimensions are written using the Structured Query Language (SQL). All SQL syntax supported by the PostgreSQL DBMS can be leveraged. The use of the star or snowflake schema design encourages the use of a repeatable SQL pattern for most queries. This pattern is as follows:
Typical Design of a Dimensional Model Query
SELECT column, column, …
FROM fact_table
JOIN dimension_table ON dimension_table.primary_key = fact_table.foreign_key
JOIN …
WHERE dimension_table.column = some condition …
… and other SQL constructs such as GROUP BY, HAVING, and LIMIT.
The SELECT clause projects all the columns of data that need to be returned to populate or fill the various aspects of the report design. This clause can make use of aggregate expressions, functions, and similar SQL syntax. The FROM clause is built by first pulling data from a single fact table and then performing JOINs on the surrounding dimensions. Typically only natural joins are required to join against dimensions, but outer joins may be required on a case-by-case basis. The WHERE clause in queries against a dimensional model will filter on conditions from the data either in the fact or dimension based on whether the filter numerical or textual.
The data types of the columns returned from the query will any of those supported by the PostgreSQL DBMS. If a column projected within the query is a foreign key to a dimension and there is no appropriate value, a sentinel will be used depending on the data type. These values signify either not applicable or unknown depending on the dimension. If the data type cannot support translation to the text “Unknown” or a similar sentinel value, then NULL will be used.
| Data type | Unknown value |
|---|---|
| text | ’Unknown’ |
| macaddr | NULL |
| inet | NULL |
| character, character varying | ‘-’ |
| bigint, integer | -1 |
The first line of a query cannot be a SQL comment. Any SQL comment used in the query must not contain a semi-colon.
Data model 2.0.0 exposes information about linking assets across sites. All previous information is still available, and in the same format. As of data model 2.0.0, there is a sites column in the dim_asset dimension that lists the sites to which an asset belongs.