Architecture Overview
Digital Risk Protection (Threat Command) performs constant threat intelligence monitoring across all web sources: clear web, deep web, and dark web. In addition, Digital Risk Protection (Threat Command) utilizes “piggybacking” in existing search engines to gather further information. All the data is gathered by a unique browsing solution, which bypasses the various obstacles on the dark web, for example, anti-bot technologies.
The data is stored in Digital Risk Protection (Threat Command) databases and then undergoes sophisticated analysis. The Digital Risk Protection (Threat Command) algorithms ensure the relevancy and nature of each cyber threat before they are forwarded to the user.
The information is classified according to end-user relevance, and then pushed to the end-user via the cloud-based Digital Risk Protection (Threat Command).
The following figure shows the threat alert process, with a sample of collection sources:
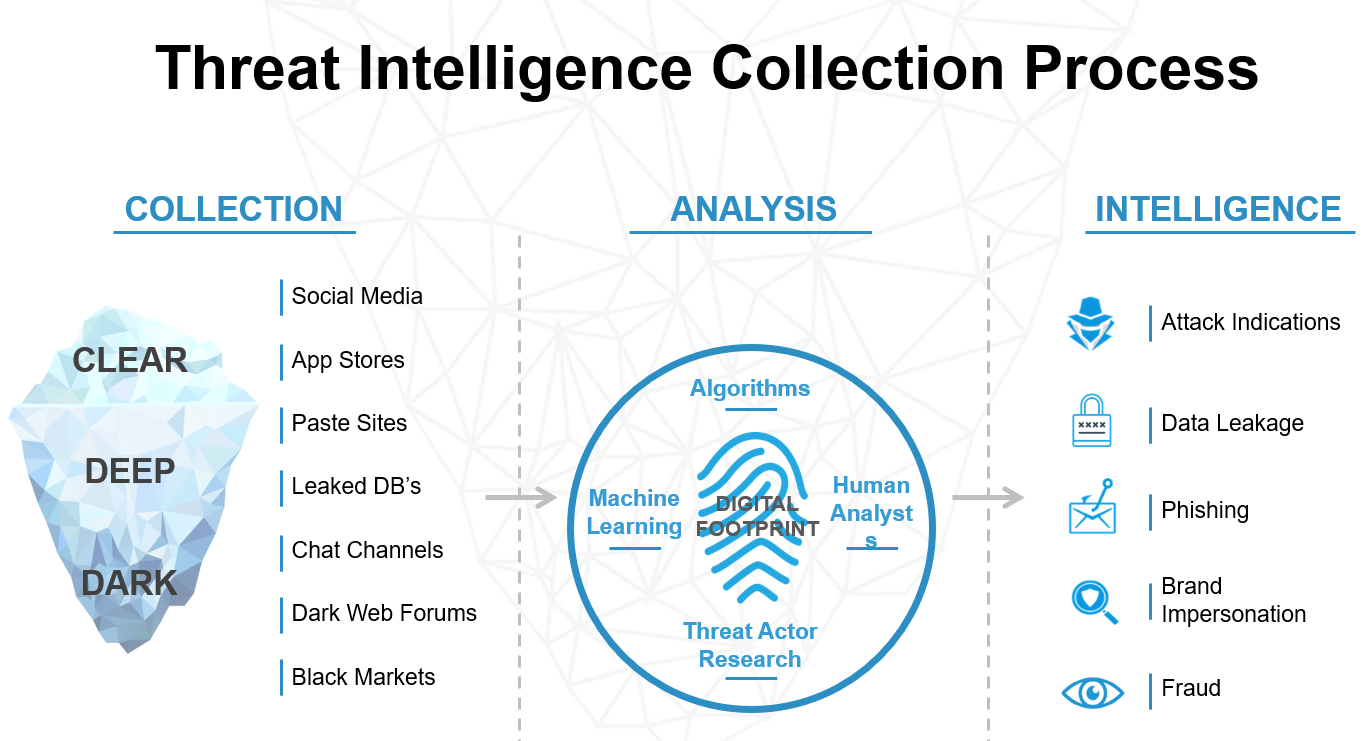
Digital Risk Protection (Threat Command) threat intelligence collection process
The Digital Risk Protection (Threat Command) Alerts page enables users to manage and mitigate alerts.
Management tools:
- Share the alert
- Ask an analyst
- Assign the alert
- Investigate
- Close
- Many other tools
Mitigation tools:
- Remediation options
Collection
The Digital Risk Protection (Threat Command) web-crawling solution imitates human behavior with a real web browser. This enables the scraping of data from various sources including cyber-crime forums, web chats, black markets, and other threat arenas without being banned, as well as the ability to crawl the clear, deep, and dark webs.
This technology is used to collect data in the following ways:
- Searching - Detect cyberthreats relevant to Digital Risk Protection (Threat Command) users. This method is used only for legitimate and well-known information sources. This way, there is no chance of attribution or exposure of customer assets.
- Scraping/Crawling - Collect all the data from a given source. Once the data is collected, it is stored in Digital Risk Protection (Threat Command) databases for further analysis. This method keeps the customers’ data (assets) undisclosed, as they are only used in the analysis phase, and these assets are never revealed to the data source.
- For example, instead of searching for customer-related data inside a cyber-crime forum (which would reveal assets), every post published on the forum will be scraped and stored in Digital Risk Protection (Threat Command) databases for further, customer-based analysis.
Source coverage
To provide customers with the most comprehensive threat intelligence visibility, Digital Risk Protection (Threat Command) focuses on wide coverage of intelligence sources.
The following list cites example sources:
-
Clear web
- Search engines
- Paste sites
- Social media networks
- Application stores
- Image boards
- Other clear web sources
- Document-sharing websites
-
Dark and deep web
- Cybercrime forums
- Black markets
- IRC channels
- Other dark and deep web sources
In addition to the data sources listed above, Digital Risk Protection (Threat Command) reaches millions of relevant sources by “piggybacking” on several prominent search engines.
Analysis
Before forwarding an alert to a user, Digital Risk Protection (Threat Command) analyzes the threat. The analysis phase determines if a specific webpage, domain, or application poses a cyber threat, its relevance to the customer, and the alert classification. Analysis uses statistical machine-learning-based algorithms that analyze each web page, domain, or application and output a threat score. If the threat score exceeds a certain threshold, it is forwarded for further classification, and only then reported to the customer.
Cross-validation and false positives
To minimize the number of false positives, Digital Risk Protection (Threat Command) has implemented a cross-validation workflow. In this workflow, every alert that receives a relatively low score is validated by an analyst for a yes/no decision before the alert is delivered to the customer. Analyst intervention is minimal and occurs only in extreme cases. In addition, an Digital Risk Protection (Threat Command) analyst manually searches for threats based on customer priorities and their threat profile. Only 2-3% of alerts presented to a customer are false positives.