Crawler Restrictions
You may often need to test a specific area of your web application, such as the home page, or prevent scanning certain areas such as the admin panel. The Crawler Restrictions tab allows you to set a URL allowlist or denylist for crawling.
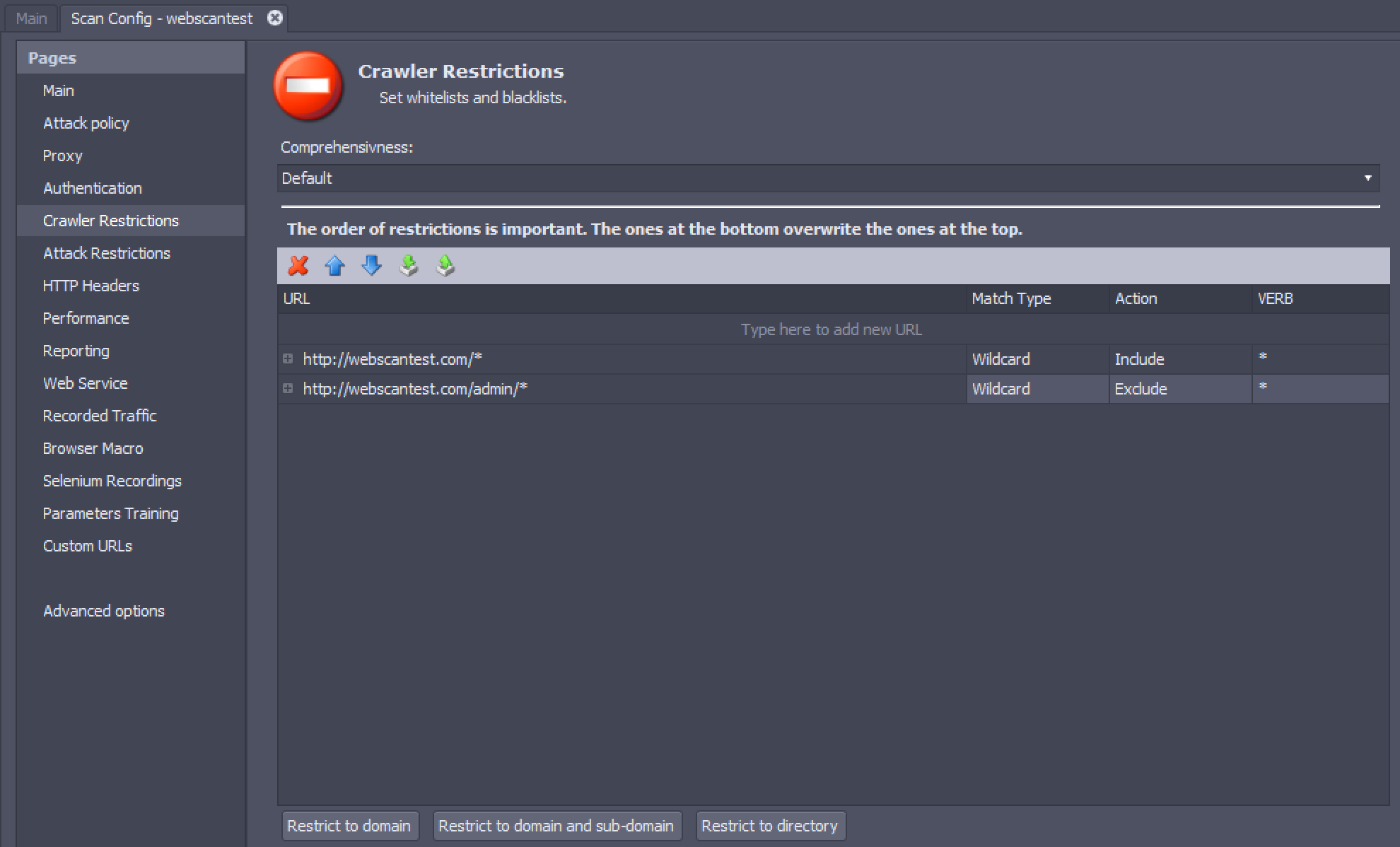
When a scan begins, AppSpider visits the seed URLs specified in the Main Settings. It then visits all the pages linked to the seed URLs recursively, making an inventory of pages, directories, and parameters in the application. AppSpider will match the URL of each page it discovers with each entry in the crawler restrictions list from top to bottom. The last restriction that matches the URL is used to decide whether the URL will be included or excluded from the scan. If no restriction matches the URL, it will not be crawled. For example, using the restrictions in the screenshot, http://webscantest.com/datastore/items will be included in the scan but http://webscantest.com/datastore/admin/settings.html will be excluded.
Crawler restrictions cannot be empty. If you do not provide crawler restrictions, they will be automatically generated from your seed URLs. You can remove and edit the order of restrictions using the Delete, Move Up and Move Down buttons.
Comprehensiveness Setting
The Comprehensiveness setting controls how exhaustively AppSpider crawls your app. You can use this setting to improve the scan speed. The Comprehensiveness setting has two possible values:
- Default - AppSpider will crawl a sample of discovered pages that provide a good representation of the web site.
- Fast Scan - AppSpider will reduce the number of times it crawls and attacks similar looking URLs and parameters.
Crawler Restrictions Table
Crawler restrictions enable you to control the portions of the application being crawled. The Crawler Restrictions table contains the following columns:
- URL - This field can have a complete URL or a URL with wildcards or regular expressions.
- Match type - This field controls the logic used to match URLs discovered in scans with the URL provided in the crawl restriction. It can have the following possible values:
- Wildcard - Accounts for wildcard characters in the crawl restriction while matching with the discovered URL. The
*wildcard character matches any symbol while?matches one symbol. - Literal - Matches the discovered URL with the exact string the crawl restriction.
- Regex - Accounts for regular expressions in the crawl restriction while matching with the discovered URL. The regex must be a valid URL starting with
http(s)?://.
- Wildcard - Accounts for wildcard characters in the crawl restriction while matching with the discovered URL. The
- Action - This field has the following values:
- Include - Include the URL in the crawl.
- Exclude - Exclude the URL from the crawl and do not scan it.
- Verb - “Verb” is a Web verb such as GET, POST, or PUT. You can learn more about Web verbs here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods . By default, crawler restrictions are applied to all verbs, but you can provide restrictions specific to a particular verb.
Crawler Restrictions Buttons
You can use the buttons below the Crawler Restrictions table to reset the crawler restrictions and apply new restrictions based on the seed URLs. If we assume that the seed URL is http://webscantest.com/datastore/, the buttons will perform the following actions:
- Restrict to domain - Restrict the scan to the domain of the seed URL. (
http://webscantest.com/datastore/>http://webscantest.com/*) - Restrict to domain and subdomain - Restrict the scan to the domain and subdomains of the seed URL. (
http://webscantest.com/datastore/>http://*.webscantest.com/*) - Restrict to directory - Restrict the scan to the directory of the seed URL. (
http://webscantest.com/datastore/>http://webscantest.com/datastore/*)
How to Use Crawler Restrictions
Here are some scenarios where you can use crawler restrictions to make your scans more efficient:
- On multilingual sites, you can set your crawler restrictions to only cover one language to reduce redundancy and improve scan performance:
https://www.AppSpiderTarget.com/en/* Wildcard Include- You can avoid a specific part of the site that has functionality you don’t want to trigger. Use wildcards to avoid entire sections or literals to avoid specific pages or parameters:
https://www.AppSpiderTarget.com/postABlog/ Literal Exclude
https://www.AppSpiderTarget.com/contactUs/ Literal Exclude
https://www.AppSpiderTarget.com/adminPanel/* Wildcard ExcludeIn cases where the functions to exclude can appear anywhere within the directory tree, you can use a regex match type:
http(s)?://(.)+(postReview)(.)? Regex Exclude- On very large sites, you might want to scan with multiple configurations. Each config would cover a portion of the site, rather than the whole site at once. This would give you better control of the scan times and allow for a faster time to remediation.
Scan Config A:
https://www.AppSpiderTarget.com/products/categories/A/* Wildcard Include
https://www.AppSpiderTarget.com/products/categories/B/* Wildcard Include
https://www.AppSpiderTarget.com/products/categories/C/* Wildcard Exclude
https://www.AppSpiderTarget.com/products/categories/D/* Wildcard ExcludeScan Config B:
https://www.AppSpiderTarget.com/products/categories/A/* Wildcard Exclude
https://www.AppSpiderTarget.com/products/categories/B/* Wildcard Exclude
https://www.AppSpiderTarget.com/products/categories/C/* Wildcard Include
https://www.AppSpiderTarget.com/products/categories/D/* Wildcard Include- You can use the VERB value to exclude HTTP methods that you do not want to be called by the scan engine:
https://AppSpiderTarget.com/* Wildcard Exclude POST
https://AppSpiderTarget.com/* Wildcard Exclude PUT