Data-centric risk prioritization
If your organization uses hybrid or multi-cloud environments, you may find yourself managing increasingly complex, sensitive data on a daily basis. Data can be duplicated, misplaced, or exposed due to insufficient visibility, poor data hygiene, and lack of governance. Your internal teams can struggle to track who may have access to data, to protect the data, and to verify compliance with evolving privacy regulations. Any of these gaps can lead to breaches, regulatory fines, and reputation damage.
Cloud Security (InsightCloudSec) offers an integrated sensitive data discovery capability that can provide you with a unified approach to managing sensitive data discovery risks across your environments. This capability seamlessly combines sensitive data insights with the existing risk scoring and prioritization model introduced with Layered Context but found throughout Cloud Security (InsightCloudSec). Now your teams can have global data visibility, assisting them with tracking sensitive data assets across locations, ownership, access controls, posture statuses, and usage.
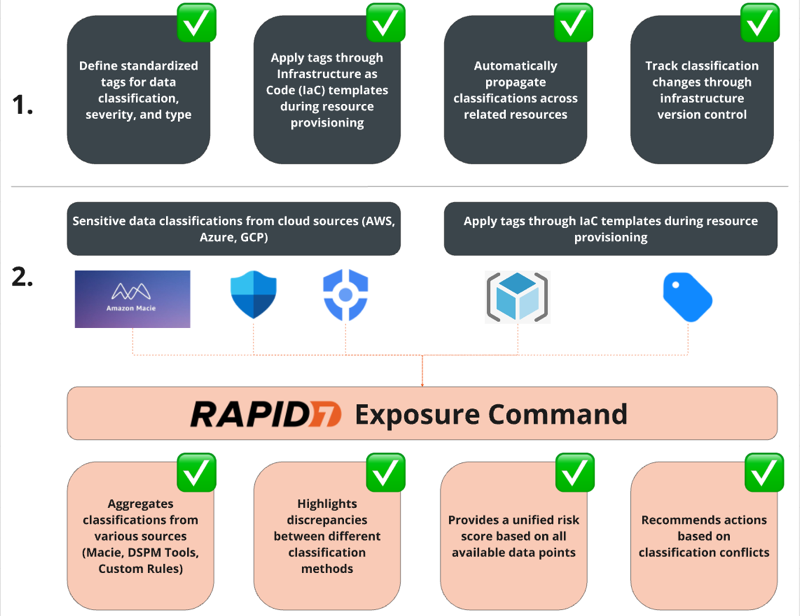
Currently, Cloud Security (InsightCloudSec) supports sensitive data classification using resource tags as well as reporting based on sensitive data discovery findings from third-party services. Using other features found in Cloud Security (InsightCloudSec), you can proactively mitigate sensitive data risks or eliminate issues before they occur:
- Cloud Summary (Risk Overview) - Assess the risk of your environments at a high level and learn how many resources contain sensitive data in your environment on a daily basis
- Resources Inventory - Review individual risk assessments and sensitive data types and severity found on resources in your environment
- Layered Context - Discover the resources with the most impactful risk, including ones with sensitive data of any severity
- Attack Paths - Discover if resources with sensitive data are found on a path that any effective attacker could exploit
- Infrastructure as Code - Proactively classify resources as they are deployed and automatically fail deployments that are missing data classification
- Bot Factory - Leverage automated tagging on supported resources using a defined data classification format to prioritize risk and improve security posture
For details on setting up and using this capability, explore Set up and use sensitive data classifications.
Frequently Asked Questions (FAQs)
Is Rapid7 defining what is sensitive data or are those definitions from the cloud service providers?
Rapid7 currently provides visibility into AWS, Azure, and GCP’s service offerings, but you can also manually specify classifications using tagging.
How much impact does sensitive data have on a resource’s risk score?
When assessing a score for an AWS Storage Container (S3 Bucket), the score is impacted based on volume of data found as well as severity of the classification. All other supported resources scores are only impacted by severity of the classifications.
If you manually classify a resource as a certain severity, does it override the cloud service providers’ classification??
Yes, manual severity classifications take priority over a cloud service provider’s classification.
Can you upload your own data that specifies what is personally identifiable information (PII) for your organization or manage a custom allowlist for certain types of data?
Currently, Cloud Security (InsightCloudSec) does not natively support this functionality, but you could update the CSP service for custom identifiers or manually classify resources.