Planning your Scan Engine Deployment
Your assessment of your security goals and your environment, including your asset inventory, will help you plan how and where to deploy Scan Engines. Keep in mind that if your asset inventory is subject to change on continual basis, you may need to modify your initial Scan Engine deployment over time.
Any deployment includes a Security Console and one or more Scan Engines to detect assets on your network, collect information about them, and test these assets for vulnerabilities. Scan Engines test vulnerabilities in several ways. One method is to check software version numbers, flagging out-of-date versions. Another method is a “safe exploit” by which target systems are probed for conditions that render them vulnerable to attack. The logic built into vulnerability tests mirrors the steps that sophisticated attackers would take in attempting to penetrate your network.
The application is designed to exploit vulnerabilities without causing service disruptions. It does not actually attack target systems.
One way to think of Scan Engines is that they provide strategic views of your network from an attacker’s perspective. In deciding how and where to deploy Scan Engines, consider how you would like to “see” your network.
View your network inside-out: hosted vs. distributed Scan Engines
Two types of Scan Engine options are available—hosted and distributed. You can choose to use only one option, or you can use both in a complementary way. It is important to understand how the options differ in order to deploy Scan Engines efficiently. Note that the hosted and distributed Scan Engines are not built differently. They merely have different locations relative to your network. They provide different views of your network.
Hosted Scan Engines allow you to see your network as an external attacker with no access permissions would see it. They scan everything on the periphery of your network, outside the firewall. These are assets that, by necessity, provide unconditional public access, such as Web sites and e-mail servers.
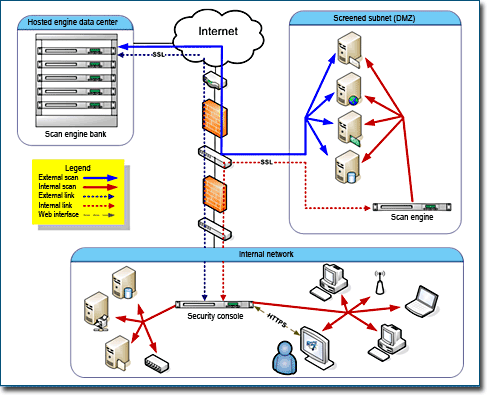
If your organization uses outbound port filtering, you would need to modify your firewall rules to allow hosted Scan Engines to connect to your network assets.
Rapid7 hosts and maintains these Scan Engines, which entails several benefits. You don’t have to install or manage them. The Scan Engines reside in continuously monitored data centers, ensuring high standards for availability and security.
With these advantages, it might be tempting to deploy hosted Scan Engines exclusively. However, hosted Scan Engines have limitations in certain use cases that warrant deploying distributed Scan Engines.
Distribute Scan Engines strategically
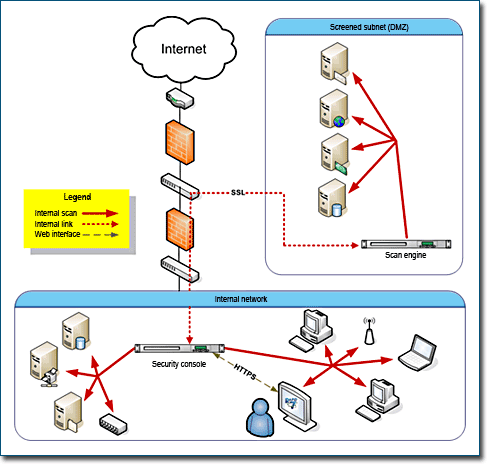
Distributed Scan Engines allow you to inspect your network from the inside. They are ideal for core servers and workstations. You can deploy distributed Scan Engines anywhere on your network to obtain multiple views. This flexibility is especially valuable when it comes to scanning a network with multiple subnetworks, firewalls, and other forms of segmentation.
Scan Engines do not store scan data. Instead, they immediately send the data to the Security Console.
Prior to deploying your Scan Engines, you should first consider where to put them.
To determine where to put Scan Engines, it can be helpful to look at your network topology. You should consider the areas of separation and connecting points.
It is possible to operate a Scan Engine on the same host computer as the Security Console. While this configuration may be convenient for product evaluation or small-scale production scenarios, it is not appropriate for larger production environments, especially if the Scan Engine is scanning many assets. Scanning is a RAM-intensive process, which can drain resources away from the Security Console.
Following are examples of situations that could call for the placement of a Scan Engine.
Firewalls, IDS, IPS, and NAT devices
You may have a firewall separating two subnetworks. If you have a Scan Engine deployed on one side of this firewall, you will not be able to scan the other subnetwork without opening the firewall. Doing so may violate corporate security policies.
An application-layer firewall may have to inspect every packet before consenting to route it. The firewall has to track state entry for every connection. A typical scan can generate thousands of connection attempts in a short period, which can overload the firewalls state table or state tracking mechanism.
Scanning through an Intrusion Detection System (IDS) or Intrusion Prevention System (IPS) can overload the device or generate an excessive number of alerts. Making an IDS or IPS aware that Vulnerability Management is running a vulnerability scan defeats the purpose of the scan because it looks like an attack. Also, an IPS can compromise scan data quality by dropping packets, blocking ports by making them “appear” open, and performing other actions to protect assets. It may be desirable to disable an IDS or IPS for network traffic generated by Scan Engines.
Having a Scan Engine send packets through a network address transition (NAT) device may cause the scan to slow down, since the device may only be able to handle a limited number of packets per second.
In each of these cases, a viable solution would be to place a Scan Engine on either side of the intervening device to maximize bandwidth and minimize latency.
VPNs
Scanning across virtual private networks (VPNs) can also slow things down, regardless of bandwidth. The problem is the workload associated with connection attempts, which turns VPNs into bottlenecks. As a Scan Engine transmits packets within a local VPN endpoint, this VPN has to intercept and decrypt each packet. Then, the remote VPN endpoint has to decrypt each packet. Placing a Scan Engine on either one side of the VPN tunnel or the other eliminates these types of bottlenecks, especially for VPNs with many assets.
Subnetworks
The division of a network into subnetworks is often a matter of security. Communication between subnetworks may be severely restricted, resulting in slower scans. Scanning across subnetworks can be frustrating because they are often separated by firewalls or have access control lists (ACLs) that limit which entities can contact internal assets. For both security and performance reasons, assigning a Scan Engine to each subnetwork is a best practice.
Perimeter networks (DMZs)
Perimeter networks, which typically include Web servers, e-mail servers, and proxy servers, are “out in the open,” which makes them especially attractive to hackers. Because there are so many possible points of attack, it is a good idea to dedicate as many as three Scan Engines to a perimeter network. A hosted Scan Engine can provide a view from the outside looking in. A local Scan Engine can scan vulnerabilities related to outbound data traffic, since hacked DMZ assets could transmit viruses across the Internet. Another local Scan Engine can provide an interior view of the DMZ.
ACLs
Access Control Lists (ACLs) can create divisions within a network by restricting the availability of certain network assets. Within a certain address space, such as 192.168.1.1/254, Vulnerability Management may only be able to communicate with 10 assets because the other assets are restricted by an ACL. If modifying the ACL is not an option, it may be a good idea to assign a Scan Engine to ACL-protected assets.
WANs and remote asset locations
Sometimes an asset inventory is distributed over a few hundred or thousand miles. Attempting to scan geographically distant assets across a Wide Area Network (WAN) can tax limited bandwidth. A Scan Engine deployed near remote assets can more easily collect scan data and transfer that data to more centrally located database. It is less taxing on network resources to perform scans locally. Physical location can be a good principle for creating a site. See Configuring scan credentials. This is relevant because each site is assigned to one Scan Engine.
Other factors that might warrant Scan Engine placement include routers, portals, third-party-hosted assets, outsourced e-mail, and virtual local-area networks.
Deploying Scan Engine Pools
If your license enables Scan Engine pooling, you can use pools to enhance the consistency and speed of your scan coverage. A pool is a group of Scan Engines over which a scan job is distributed. Pools are assigned to sites in the same way that individual Scan Engines are.
NOTE
Pre-authorized AWS scan engine Amazon Machine Images (AMIs) cannot be added to Scan Engine pools.
Pooling provides two main benefits:
- Scan load balancing prevents overloading of individual Scan Engines. When a pool is assigned to a scan configuration of a site, scan jobs are distributed throughout the pool, reducing the load on any single Scan Engine. This approach can improve overall scan speeds. It is a requirement that the Scan Engines in the pool can communicate with all assets in the scan scope.
- Fault tolerance prevents scans from failing due to operational problems with individual Scan Engines. If the Security Console contacts one pooled Scan Engine to start a scan, but the Scan Engine is offline, the Security Console simply contacts the next pooled Scan Engine. Also, the application monitors how many jobs it has assigned to the pooled engine and does not assign more jobs than the pooled engine can run concurrently based on its memory capacity. Assets are distributed to Scan Engines at the start of the scan, if the scan is disrupted due to an unexpected event with the Scan Engine such as hardware or communication failure then any assets not yet scanned by that Scan Engine will not be completed.
The algorithm for how much memory a job takes is based on the configuration options specified in the scan template.
You can configure and manage pools using the Web interface. See the Scan Engine Pools page for instructions. You also can use the extended API v1.2. See the API Guide.
Best practices for deploying and scaling pools
For optimal performance, make sure that pooled Scan Engines are located within the same network or geographic location. Geographically dispersed pools can slow down scans. For example, if a pool consists of one engine in Toronto and one in Los Angeles, and this pool is used to scan a site of assets located in Los Angeles, part of that load will be distributed to the Toronto engine, which will take longer to scan the assets because of the geographical distance.
To improve the performance of pools, you can add Scan Engines or increase the amount of RAM allocated to each pooled engine. By increasing RAM, you can increase the number of simultaneous assets that each engine scans. All Scan Engines in the pool should have the same resources. If they do not all match, the templates using the pool should be configured based upon the lowest resourced engine in the pool. See Working with scan templates and tuning scan performance.