Components for Building a Query
Before you begin writing a query, it is important to learn about the components of SIEM (InsightIDR)’s search languages and how to use their syntax correctly. This topic defines the components of LEQL and regular expression (regex), describes their use cases, and provides practical examples. As you write a LEQL query in Log Search, the query bar automatically suggests the elements of LEQL that you can use in your query. Use the up and down arrows to easily select query suggestions and then, to run a query, press Enter. When running a blank query you can press Enter or Escape.
SIEM (InsightIDR) offers you different ways to search your data, including: key-value pair (KVP), string, keyword search, and regular expression (regex).
Quotation marks
Quotation marks are used to enclose a search value in a query. There are multiple variations of quotation marks, and they serve different purposes.
If the value you are searching for contains a space, you must use double quotes.
For example, a search for the key-value pair dessert and banana pudding must be:
dessert="banana pudding"If the value you are searching for contains a single quote ‘ in the value, you must use double quotes “” to enclose the value.
where(key = "banana ' pudding")If the value you are searching for contains a double quote “, you must use single quotes to enclose the value.
where(key = 'banana " pudding')You can also use triple quotes ‘’’ regardless of the types of quotes the value contains. If the value you are searching for contains both a single quote ‘ and a double quote “, you must use triple quotes to enclose the value.
where(key = '''banana " pudding''')
where(key = '''banana " pudding''')
where(key = '''banana ' apple " pudding''')Numbers
Numeric values in queries must be in these formats:
- Signed or unsigned integers
- Floating-point values
- Simple or scientific notation
For the best search results, numeric values should fit in ranges of Java Double or Long data types. Otherwise, the value will be treated as a string.
Examples
answer = 42
time_dif < -1e-03
PI >= 3.1415
A = 6.0221409e+23For example, a search for the key-value pair my_key and 1000 must be:
my_key = 1000
my_key = 1e3
my_key = 1.0e+03
my_key = 1000.0Operators
SIEM (InsightIDR) supports both logical and comparison operators, which allow you to create more complex searches.
Format numerical values
Numerical values must be formatted as an integer, floating-point value, or in scientific notation to be properly recognized. Units are not calculated as part of the comparison. For example, searching for a value<100bytes would not return a result with value=200bits.
Logical Operators
SIEM (InsightIDR) supports the AND, OR, and NOT logical operators to help you create comprehensive search criteria.
Note: Logical operators are treated as case-insensitive by LEQL.
| Logical Operator | Example | Description |
|---|---|---|
AND | expr1 AND expr2 | Returns log events that match both criteria |
OR | expr1 OR expr2 | Returns log events that match one or both criteria |
NOT | expr1 NOT expr2 | Returns log events that match expr1 but not expr2 |
Comparison Operators
Comparison operators can be used for KVP searches and regex searches. Comparison operators such as <, >, \<= , >= support values that include numbers with units.
| Comparison Operator | Example | Description |
|---|---|---|
= | field = value | Returns log events that match the search value – matches text and numeric values |
!= | field != value | Returns log events that do not match the search value – matches text and numeric values |
> | field > num | Returns log events with field values higher than the search value |
>= | field >= num | Returns log events with field values higher than or equal to the search value |
< | field < num | Returns log events with field values lower than the search value |
\<= | field <= num | Returns log events with field values lower than or equal the search value |
== | fieldA == fieldB | Returns log events where the key values are the same. Use this operator to compare keys. You can compare strings or numeric values |
!== | fieldA !== fieldB | Returns log events where the key values are not the same. You can input strings or numeric values |
CONTAINS | field CONTAINS value | Returns log events where the values contain specified text values |
ICONTAINS | field ICONTAINS value | Returns log events where the values case-insensitively contain specified text values |
STARTS-WITH | field STARTS-WITH value | Returns log events where the values start with specified text values |
ISTARTS-WITH | field ISTARTS-WITH value | Returns log events where the values case-insensitively start with specified text values |
IN | field IN [value1, value2, value3] | A shortcut for multiple ORs, e.g. field=value1 OR field=value2 OR field=value3. Returns log events where the values match any of the criteria in the list - text, numbers, regex or CIDR, for example, source_address IN [IP(10.0.0.0/24), IP(192.168.0.0/24)]. List can contain 1 or more items. |
IIN | field IIN [value1, value2, value3] | Similarly to IN, returns log events where the values match any of the criteria in the list, but text values are compared in case-insensitive way |
CONTAINS-ANY | field CONTAINS-ANY [value1, value2, value3] | Returns log events where the values contain any of substrings in the list |
ICONTAINS-ANY | field ICONTAINS-ANY [value1, value2, value3] | Returns log events where the values case-insensitively contain any of substrings in the list |
CONTAINS-ALL | field CONTAINS-ALL [value1, value2, value3] | Returns log events where the values contain all of substrings in the list |
ICONTAINS-ALL | field ICONTAINS-ALL [value1, value2, value3] | Returns log events where the values case-insensitively contain all of substrings in the list |
STARTS-WITH-ANY | field STARTS-WITH-ANY [value1, value2, value3] | Returns log events where the values start with any of substrings in the list |
ISTARTS-WITH-ANY | field ISTARTS-WITH-ANY [value1, value2, value3] | Returns log events where the values case-insensitively start with any of substrings in the list |
NOCASE() | field = NOCASE(value) | Returns log events that case-insensitively match the search text or numeric value |
Exclude results with comparison operators
You can use NOT or ! along with comparison operators to exclude data from your query results.
You must use NOT in front of these operators to exclude data from your results:
- CONTAINS
- ICONTAINS
- STARTS-WITH
- ISTARTS-WITH
- IN
- IIN
- CONTAINS-ANY
- ICONTAINS-ANY
- CONTAINS-ALL
- ICONTAINS-ALL
- STARTS-WITH-ANY
- ISTARTS-WITH-ANY
Examples
where(key NOT IN ["aaa", "bbb"])
where(key1, key2 NOT STARTS-WITH "aaa")You must use ! before these operators to exclude data from your results:
=>>=<\<===
Examples
key != ["aaa", "bbb"]
key1, key2 !> "aaa"Compound Keys
You can check multiple keys against the same value and reduce repetition in queries with the help of compound keys. Depending on the syntax and format you use, a comma can act as an OR or an AND operator.
Instead of entering this query into your search bar:
where(key1="abc" OR key2="abc")Simply enter the keys you want to search for the value of separated by a comma to use the comma like an OR operator:
where(key1,key2 = "abc")You can add the word all to a query to make the comma act as an AND operator:
where(all(key1, key2) IN [value1, value2])Order of Operation
As with other query languages, LEQL follows boolean logic rules and respects parentheses. This should be considered if you want to control the operator precedence that the query follows.
To understand the operator precedence of AND and OR operators in LEQL, it helps to consider a simple math equation.
In basic mathematics, multiplication, division, addition, and subtraction are the operations. We know that multiplication and division have higher precedence than addition and subtraction. And so, if we want to modify that behavior, we use parentheses.
For example, in this equation, multiplication is done before addition:
1 + 2 * 3 = 7In this equation that contains parentheses, multiplication is after addition:
(1 + 2) * 3 = 9The same concepts apply to LEQL:
ANDoperators are evaluated firstORoperators are evaluated second- If you want to modify this behavior, use parentheses.
Examples
You have these key-value pairs in your log data:
"city": "London" "action": "login" To query for logins in either London or Dublin, you would enter:
where((city = London OR city = Dublin) AND action = login)You can override the operator precedence of the AND and OR operators by adding a set of parentheses around the key-value pairs of both cities.
Keyword Search
Keyword search works on all logs, regardless of their format. Keyword searches match the full string listed in a query until the string is separated by whitespace or a non-letter character on both sides of the string.
Note: Keyword searches are case-sensitive by default.
Examples
You have log entries that looks like this:
Apr 13 20:01:01 hostname run-parts(/etc/cron.hourly)[26263]: starting 0anacron
Apr 13 20:01:01 hostname run-parts(/etc/cron.hourly)[26272]: finished 0anacronYou run the query:
where(run)In the log entries, “run” is delimited by whitespace and a dash. Because of these delimiters, Log Search will return these log entries in the results.
Keyword search can also be combined with logical operators and quotes.
For example, the query where(Amazon AND Boardman) will return results where both “Amazon” and “Boardman” appear in the same log entry.
The query where("Amazon Boardman") will return results where the keyword “Amazon Boardman” appears in the log entry.
Use quotation marks to match exact strings
When you list a series of keywords, SIEM (InsightIDR) automatically assumes an AND operator between each keyword. If you want to match an exact string, place quotation marks “” around the search.
Regular Expression Keyword Search
Regular expressions (regex) can add more precision to your keyword searches. Regex must be wrapped with two forward slashes //.
Partial Matching
By default, regex searches will return partial matches.
Example
where(/complete/)This query returns results that match “complete,” “completely,” and “completed”.
Case Insensitive Search, Partial Matching, and Comparison
To perform a case-insensitive keyword search for the word “error”, you can use this format:
where(/error/i)This query matches instances of the word “error”, such as, Error, ERROR, error, and any other case variation.
You can query keys that contain a specific value, regardless of case, by using the NOCASE function:
where(key = NOCASE(value))You can also query a key that contains a value anywhere in the string, regardless of case, by using the ICONTAINS function:
where(key ICONTAINS value)You can use a loose search to find case insensitive and partially matched query results. This can be useful if you don’t know the full keyword you want to match, or can’t remember the case of the keyword you’re looking for.
For example, if you are searching for the term admin without using a loose search, you could search for this keyword in a few different ways:
- Match the complete word and case for this log entry for returned results
- Use the regex
where(/admin/i)to find case insensitive and partial matches - Use
where(user = /.*admin.*/i)for case insensitive and partial matching against a specific field
Instead of using regex, you can append loose to your query to quickly find all log entries where the word “admin” is present.
where(user=admin, loose)You might have a log entry that contains irregular capitalization of values like this:
key1=VALUE0 key2=vaLueTo perform a case-insensitive key comparison, you can use this query format:
where(key1==key2, loose)The case-insensitive key comparison query finds results where the value of “key1” fully contains the value of “key2” at any position, regardless of the case of the characters.
Regular Expression Operators
Regex uses special characters to allow you to search for more advanced patterns. These characters are *, +, ., \, [], (), {}. If you need to use special characters as ordinary characters, you will need to escape them with a backward slash \.
For example, this query will find any log entries where the date field equals a day month 05 (May).
where(date=/05\/\d{2}\/2023/)Regular Expression Field Extraction
Regex grouping and naming allows you to identify values in your log events and give these values a name, similar to the key-value pair (KVP) structure. You can then use this named capturing group to perform more complex search functions.
If logs are not in the desired key-value pairs, you can Create Custom Parsing Rules or use named capturing groups to parse the log data.
For example, what if you wanted to extract the IP address from the following raw log data?
<11>Mar 14 09:24:58 _hostname_ SSH: No User. Possible reasons: Invalid username, invalid license, error while accessing user database <SessionID=33711845, Listener=10.224.9.243:22, Client=13.91.103.73:1984, User=elasticsearch>You can use this query to find the IP as a source_address:
where(/Client=(?P<source_address>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/) groupby(source_address) calculate(count)Benefits
Regex field extraction uses standard RE2 regex syntax. With field extraction, you can identify key pieces of information in your logs that are not in a key-value pair format, so that you can search the values in your logs accurately. Because field extraction is not depending on any log type or structure, you can create a type of key-value pairing out of non-key-value pair log formats.
Assign a name to the identified value(s) to use our advanced search capabilities such as groupby() or for calculating values such as counts, sums, averages or unique instance counts. You can also use the values for comparisons when creating detection rules or save the value(s) for later use in dashboards and cards.
To include a named capturing group in your regular expression, use this syntax:
(?P<name>regExp)The result returned from the query to the right of the > will be assigned the name enclosed in the < >.
Consider the sample log events below that contain a specific value such as “total sale”:
12:12:14 new sales event – customer Tim – total sale 24.45 – item blanket
12:12:15 new sales event – customer Tim – total sale 100.45 – item jacket
12:12:16 new sales event – customer Tim – total sale 1000.33 – item computerThe regex to find the value “total sale” and assign this value to a named variable called saleValue is:
where(/total sale (?P<saleValue>\d*)/)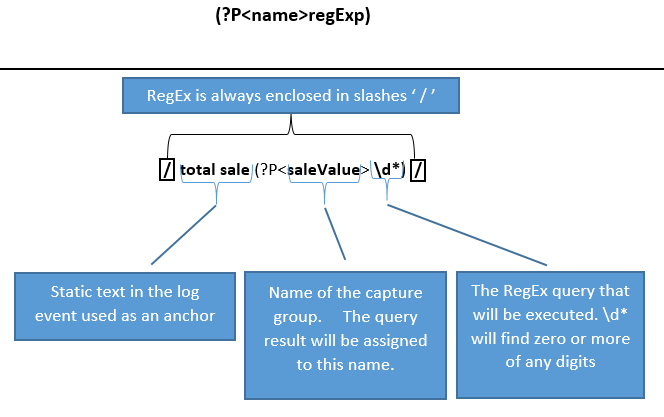
Once you have captured the key you can then perform the full range of LEQL functions against it. For example:
where(/total sale (?P<saleValue>\d*)/) calculate(average:saleValue)In the example, saleValue is the name that the digits that follow “total sale” will be assigned because of the regex. Once the digits are assigned to saleValue, then an average calculation can be applied to these numbers.
Regex field extraction is extremely useful in this scenario because the value is not in a KVP format, making it hard to tell most systems what value to use. By using regex named capturing group syntax, it is now easy to identify the value and assign it a name. This name is then used as part of the search query. It is also possible to save the query and use it for creating a dashboard item.
Key-value pair and JSON search
To understand how to write KVP and JSON searches, let’s look at an example.

Search for all log events with a response time over 25 to return the first two log events, such as:
where(response_time>25)You can then add the logical operator OR to include events from containerID 14 to return all three log events:
where(response_time>25 OR containerID=14)Note: Learn more about numerical values and notations in the Numbers section.
Special characters
JSON literals may contain special characters. To search for values that contain special characters, you must place the value in quotes or the special character must be “escaped” with a backslash. For example, to encode a Windows path such as C:\Windows in JSON, the backslash must be escaped with an additional backslash:
{"path": "C:\\Windows" }To find all instances of this JSON log entry, you could use one of these queries:
where(path=C:\\Windows)
where(path="C:\Windows")Note: If you choose not to enclose your value in quotes, you must add an additional backslash to correctly query the value.
Key expressions
The key of a key-value predicate can be specified in various ways.
Literal key - key = value returns log events where the field with name key matches the search value.
Nested key - obj.field1 = value returns events with a nested structure from the example log event:
{"obj":{"fld1":{"fld2":"val"}}To check if a field in an event contains a specified nested key, for example, “field1”, use this query:
obj.field1/Wildcard key - key.* = value, returns log events where a nested field of the object or an item of nested array matches the search value.
This search retrieves the log events like:
{"key": {"field1": "value", "field2": "garbage"}} and {"key": ["value", "garbage"]}The same results can be achieved using:
key.field1 = value
key.field2 = value AND key.0 = value
key.1 = valueWildcard keys not only simplify search queries, but also allow finding log events with unknown field names and arbitrary order of array items. To search for log events with more complicated structure it’s possible to specify more than one wildcard symbol, for example:
key.*.field1.* = valueThe query key, key1, key2 = value, returns log events where any of the keys match search value. Two or more keys can be specified, and each key can be a literal or wildcard key. You can also list the KVPs you’re searching for, separated by OR to yield the same results: key1 = value OR key2 = value.
The query ALL(key1, key2) = value, returns log events where all keys match the specified value. Two or more keys can be specified, each key can be a literal or wildcard key. You can also list the KVPs you’re searching for, separated by AND to yield the same results: key1 = value AND key2 = value.
IP Search
SIEM (InsightIDR) supports classless inter-domain routing (CIDR) notation, which allows you to search for a range of IP addresses on your network without using complicated regex. This means you can easily view the most active servers, users, and applications on your network.
CIDR notation in SIEM (InsightIDR)
You can use this capability to search flow data generated by the Rapid7 Network Sensor (Insight Network Sensor) and any log data that contains IPv4 Addresses. This requires a key-value pair search. IP() on its own does not work. Allowed subnet values are /1 to /32.
In Log Search, enter this query:
where(destination_address = IP(192.168.0.0/24))The query would return any addresses in the range 192.168.0.0 to 192.168.0.255.
- destination_address is the field in the log data you want to filter by
- 192.168.0.0 is the IP address used to calculate the subnets
- /24 is the block of addresses you want to search
You can adjust the network range of your query by updating the subnet value. For example, replacing /24 with /16 would return any addresses in the range 192.168.0.0 to 192.168.255.255.
Clauses, Analytic Functions, and Visualizations
With our powerful LEQL clauses and functions, you are able to produce queries that will easily visualize your data without any preprocessing required.
Tip for using the context menu
Select a clickable key or value to open the Log Search context menu. This menu allows you to quickly add a clause, function, key-value pair, or value the query bar. By highlighting a specific value and leveraging this menu, you can dive deeper into the data you want to understand.
Groupby
The groupby() clause allows you to group your log data by keys to find patterns and visualize your results with charts for deeper understanding.
How does deduplicated data affect query results?
If you use the count function to query the DNS Query, Firewall Activity, or Web Proxy Activity log sets, the calculation uses the observation_count value from deduplicated lines to ensure accurate results. Learn more about data deduplication.
For example, this query groups log entries by the unique values for the destination_user key:
groupby(destination_user) calculate(count)This example returns a list of all the unique usernames that are found in the destination_user field, with a count of the number of times the username was found. The most common username is listed first, followed by the rest of the usernames in descending order from most common to least common.
You can modify your groupby() query results in four ways:
- Group results by more than one field using multiple keys in a
groupby()clause. - Reduce the number of groups that are returned using the
having()clause. - Change the number of groups that are returned using the
limit()clause. - Sort results in ascending or descending order using the
sort()clause.
Statistical approximation
If more than 10,000 unique groups are found, then the results will be a statistical approximation, rather than a literal count. It’s also possible that no groups will be displayed, due to the distribution of the data.
To get an exact result, narrow your search criteria. You can do this by selecting fewer logs, a shorter time frame, or adding more search filters.
Group your log data by more than one field with a multi-groupby query
The LEQL groupby() clause allows you to group by multiple fields in your log data. Run a single query to get an overall view of your log data, as well as drill down into that data. To use this feature, add up to 5 fields in a groupby() query. You can do this by entering additional keys in the query bar.
Here is an example of a query that groups by multiple keys:
groupby(destination_user, result, service, source_asset_address) calculate(count)View the results in a table
Results are displayed in a table format, allowing you to drill into the grouped data by clicking the arrows to display subsequent fields.
Reduce the number of groups that are returned
The having() clause is used to reduce the set of groups returned when using the groupby() clause. You can leverage calculation functions, such as sum, max, and unique within the having() clause to further specify the groups returned.
The having() clause is not supported in SIEM (InsightIDR) basic detection rules. However, you can set a threshold when you create a custom detection rule to identify repeated suspicious events in your environment.
Here is an example of the results that are returned by a single groupby() query:
where(result=FAILED_BAD_PASSWORD) groupby(user)This query includes all users who have failed to log in within the specified time range, including those users who only failed once.
Here is an example of the results that are returned by a groupby() query that includes the having() clause:
where(result=FAILED_BAD_PASSWORD) groupby(user) having (count>15)This query includes users who failed to log in more than 15 times. Any users who failed to log in less than 15 times will not be included in this query’s results and could be interpreted as benign.
Here is an example of a groupby() query that includes the having() clause and calculation functions:
where(result = FAILED_BAD_PASSWORD) groupby(user) calculate(unique:geoip_country_name) having(unique:geoip_country_name>1)Required syntax for using a calculation with the having clause
You must add calculate(calculation function:key) to your query to use a calculation within the having() clause.
Group by the logs contained in your log selections
When you select a log set or multiple logs, you can use the groupby(#log) query to understand:
- How many log entries each log contains
- How frequently a key or key-value pair (KVP) appears in each log
Here are the results of an example groupby(#log) query on the Active Directory Admin Activity, Asset Authentication, and Host to IP Observations log sets:
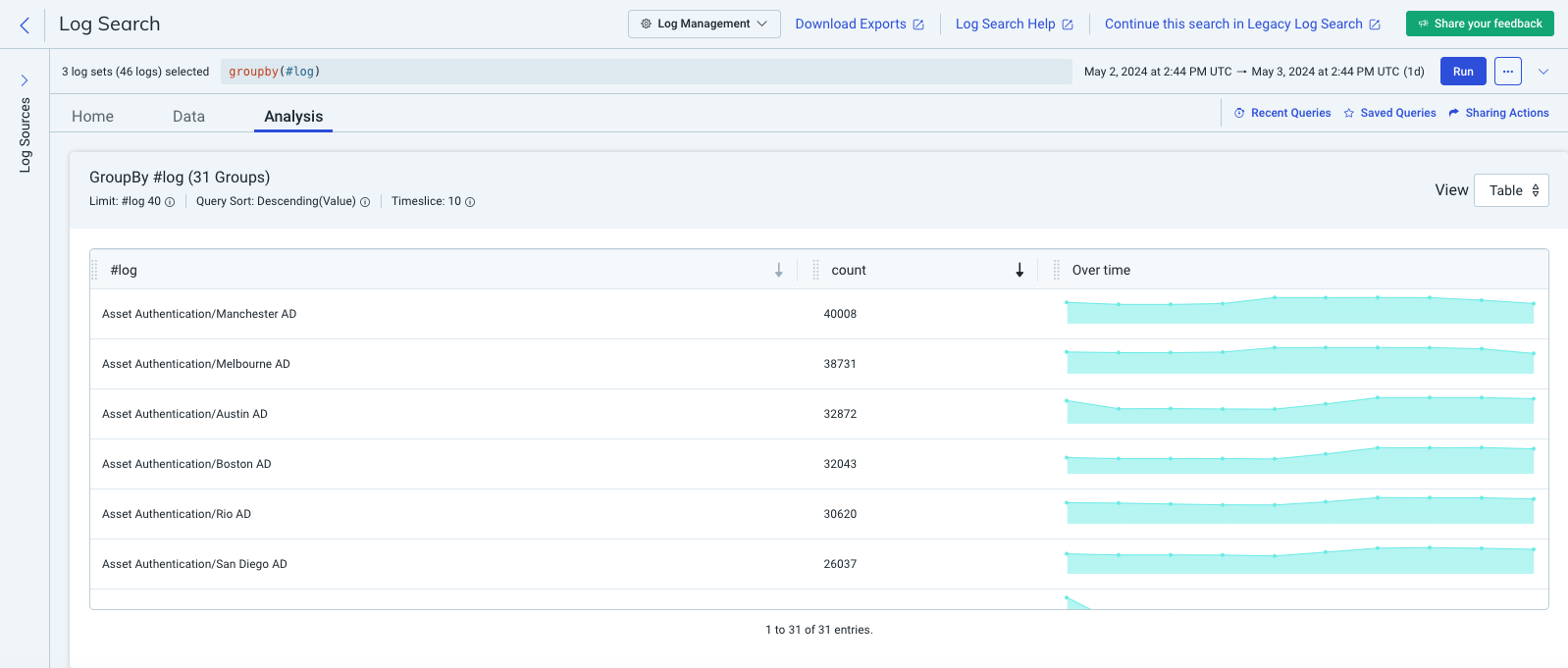
The count column lists the number of log entries that each log contains.
Here are the results of an example query that looks for a KVP in multiple logs with the help of the groupby(#log) clause.
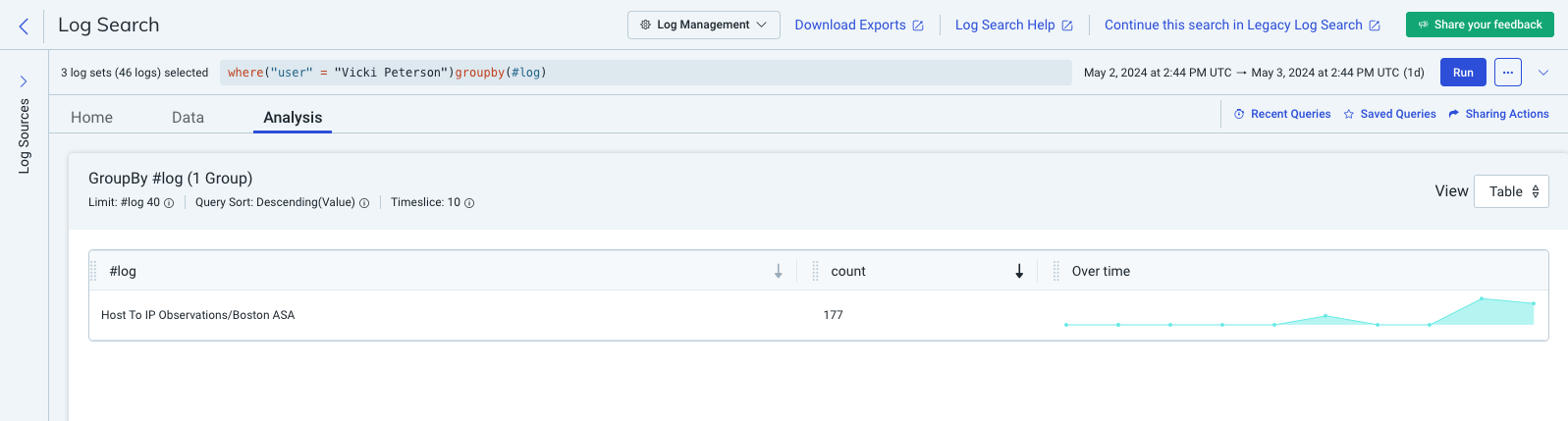
The #log column lists the log set and log where the specified KVP appears, and the count column lists the number of log entries where the KVP appears.
Literal Count
If the number of unique events in the data set is less than 10,000, the groupby() clause uses Literal Count.
Literal Count fetches every log entry in the data set and counts each occurrence of unique elements while also putting identical events together in a group.
Example
This query returns a count of unique elements, where source_address is the value you want to group by. This will return the number of unique values for the source_address key, visualized in a time based chart:
calculate(unique:source_address)When you group by keys such as unique identifiers, port numbers, or IP addresses, the number of unique values typically increases if you expand the time range. Keys that have a set number of results (SUCCESS or FAIL) will not have an increased number of values as you expand the time range.
Limit
The limit() clause will return results based on the order of operations you select in Log Search. Limit can be used by itself, in combination with the select() and where() clauses, or with a groupby() query. When used with a groupby query, the limit clause enforces the maximum number of unique values that are returned.
Results for event queries (limit(), select(), and where()) can be viewed in the Data tab, and statistical queries (groupby()) in the Analysis tab.
Change the limit for event queries
Using the limit() clause by itself or with select(), you can force the search to stop after finding the number of log events you want to view. This allows you to more strategically search your data.
Here is an example of a query that includes the where() and limit() clauses:
where("action" = "ACCOUNT_CREATED") limit(5)This query displays the 5 most recent matching results or 5 historical matches based on the order you constructed your query in (done through the user interface or API parameter). The limit clause ensures the search will stop after it finds the first 5 matches.
Change the groupby() limit
By default, LEQL limits each group to 40 results. You can change the number of groups returned by your groupby() query with the limit keyword by adding limit(n) at the end of your query, where n represents the number of groups.
Refer to the table for the maximum groups per number of group keys. Any value you input that is greater than the maximum number of groups defaults to the maximum.
| Number of group keys | Maximum groups |
|---|---|
| groupby(x0) | 10,000 |
| groupby(x0, x1) | 20,000 |
| groupby(x0, x1, x2) | 30,000 |
| groupby(x0, x1, x2, x3) | 40,000 |
| groupby(x0, x1, x2, x3, x4) | 50,000 |
This query sets a limit of 350:
groupby(source_asset_address) calculate(count) sort(desc) limit(350)If you are grouping by multiple fields, you can add in additional values to limit the number of rows returned for each individual group.
When you group by multiple fields, the limit applies across groups according to these examples:
| Query | Groupby limits |
|---|---|
| groupby(x, y) limit(5) | groupby(x, y) limit(5, 5) |
| groupby(x, y, z) limit(20, 12) | groupby(x, y, z) limit(20, 12, 12) |
| groupby(x, y) | groupby(x, y) limit(40, 40) |
This query sets a limit of 100 groups for the first key in the groupby() clause, and 20 for the second field.
groupby(source_asset_address, service) calculate(count) sort(desc) limit(100, 20)Select
To limit or manipulate the keys that are returned in your search results, add the select() clause to your query. Log Search returns results based on a default order and uses the given key names, however, by applying the select() clause, you can change the order and rename the keys.
For example, this query returns log entries that contain a “suspicious event”, but only the keys and associated values from the hostname, process.name, and process.exe_file.hashes.sha256 fields are returned in the results. The key-value pairs are returned in the order they are listed within the select clause, and renamed using the as operator based on what’s specified in the select clause: hostname to host and process.exe_file.hashes.256 to sha256hash. All other keys from matching log lines will not be included in the results allowing the user to quickly scan results of specific interest.
select (hostname as host, process.name as process, "process.exe_file.hashes.sha256" as sha256hash ) where ("suspicious event")To further limit the results of your queries, you can pair the select() clause with a where() clause.
For example, this query returns the key-value pairs for the username and hostname fields where the user failed to log in, replacing the name of those fields with “user” and “host”, respectively.
select (username as user, hostname as host) where (login!=success)Limitations
There are a few limitations to be aware of when using the select() clause:
- It can only be leveraged in the updated query bar.
- It can only be used in the updated query bar.
- It must be entered at the start of your query (the first clause).
- It supports only key literals.
- It does not support references to parent level arrays or objects.
- It does not support wildcards.
- It is not supported with the
groupby()clause or thecalculate()function. - It is not available in Legacy Log Search.
Count
Log Search also supports returning a count of matched search results. To return the number of search results, append calculate(COUNT) to your search query. For example:
where(status=500) calculate(COUNT)How does deduplicated data affect query results?
If you use the count function to query the DNS Query, Firewall Activity, or Web Proxy Activity log sets, the calculation uses the observation_count value from deduplicated lines to ensure accurate results. Learn more about data deduplication.
Sum
You can use the sum function to total the values of your name value pairs. If you had a KVP for sale_value and wanted to know the total sales for a specified time period you would use this query:
where(total_bytes>2000) calculate(SUM:total_bytes)Average
The average function is similar to the sum modifier, but it computes the mean of the values matching the search criteria. For instance, to get the average value of your sales, you might use a query like:
where(total_bytes>0) calculate(AVERAGE:total_bytes)Count Unique
The unique function returns an approximation of the number of unique values for a given key. It takes one parameter: the name of the key. For example, if you have the KVP, userID in your log file and want to find the number of unique users, you could use this query:
where(userID) calculate(UNIQUE:userID)Min
The min function returns the minimum value of the key for each time period. For example, this query will return the shortest response time for each time period:
where(status=200) calculate(MIN:responseTime)Max
The max function returns the maximum value of the key for each time period. For example, this query will return the longest response time for each time period:
where(status=200) calculate(Max:responseTime)Timeslice
By default, SIEM (InsightIDR) calculates 10 equal time intervals when using a count, min, max, or average function, or a groupby() clause. However, you can leverage the timeslice function to manually set the number of intervals using either units of time (seconds, minutes, hours, days) or whole numbers.
A valid input for the timeslice function is a number between 1 and 200 (inclusive). For example, this query could be used against a 1-hour time range to return the number of 404 errors that occurred, divided into 60 intervals.
where(status=404) calculate(count) timeslice(60)You can also specify units of time: seconds (s), minutes (m), hours (h) and days (d). For example, this query will return the number of 404 errors in 30-minute intervals.
where(status=404) calculate(count) timeslice(30m)Note: The data points on charts utilizing the timeslice function are evenly distributed to satisfy the requirements of the timeslice value.
Example
You are searching for logs in a time frame of 20 minutes from 13:00 to 13:20 and want to apply a timeslice interval of 5 minutes. You write your query and include the timeslice function: timeslice(5m). The resulting graph will contain 4 points with values shown at 13:00, 13:05, 13:10 and 13:15.
If you want to change the interval to timeslice(9m), the resulting graph will have 3 data points, because (20 minutes / 9 minutes) = 3 data points. The granularity works out as 20 minutes / 3 data points = 6 minutes 40 seconds. The 3 data points will appear at positions around 13:00, 13:06 and 13:13. And the values will be calculated on the time frames of:
- 13:00 - 13:06:40
- 13:06:40 - 13:13:20
- 13:13:20 - 13:20:00
Percentile
The percentile function allows you to exclude outliers from your search results.
Specify a percentile value by using percentile(N):key or pctl(N):key in a calculate function For example:
calculate(pctl(95):total)
Bytes
The bytes function lets you calculate the size of your logs in byte form. This is useful for users who wish to verify the size of the logs that they have sent to their account.
Use this query to calculate the size in bytes of each of your selected logs, grouped by the selected logs:
groupby(#log) calculate(bytes)Standard deviation
The standard deviation function lets you calculate the standard deviation of a given series values. This is useful when trying to establish what values would be considered within normal variance to a given mean. An example use case for standard deviation is response times.
calculate(standarddeviation:outgoing_bytes)You can also use the keyword sd as a shortcut. For example:
calculate(sd:outgoing_bytes)